PostgreSQL内核TOAST机制原理与实现
TOAST(The Oversized-Attribute Storage Technique)是PostgreSQL的一种自动存储机制,用于处理大字段的存储问题,当表中某行数据的大小超过特定值的时,会以TOAST的形式存放。
引言
通常PostgreSQL的页面大小是固定的8KB,那么对于超过单行长度超过8KB的数据(比如1MB)应该怎么存储?一种办法时将这1MB的数据按照8KB分割,存储到1MB/8KB也就是128个页面。这种方法听起来可行,但实际上不行,主要有以下原因:
- 事务与 MVCC 的简洁性 在 PostgreSQL 的 MVCC 实现中,更新一行是写入新版本,旧版本在页内或可被清理。如果一个行跨页存储,一次更新可能需要修改多个页,这会影响原子性、锁管理、回滚段(pg 没有回滚段,但有类似问题)的复杂性。跨页意味着行版本控制要跨页追踪,WAL 日志、崩溃恢复的复杂性大幅增加。
- 页内行指针(Line Pointer) 每页开头有行指针数组,指向页内的行数据位置。行指针是定长的,只能指向本页内的 offset。跨页存储会破坏这个简单结构。
- I/O 效率 即使只读一行中的一小部分字段,如果要加载多个页,会拖慢普通查询PostgreSQL 的设计是面向 OLTP 场景,希望单行较小,随机访问快。
因此从理论上来说,这种做法是可以的,但在实际上不行,而PostgreSQL采用TOAST(The Oversized-Attribute Storage Technique)机制来实现大字段存储。
TOAST的存储原理
实际上PostgreSQL有两种大对象存储方法,即TOAST和LO(Large Object),本次只讨论TOAST方法。通常当一行总大小超过 2KB 左右时会自动触发 TOAST 机制,将大字段压缩或线外存储(out-of-line)。
所谓的线外存储,指的是该字段在本行中只留一个TOAST指针(约18字节),实际数据存在一个或多个 TOAST 表中,按chunk(通常 2KB)存储,跨多个页,但逻辑上仍属于这个字段。这样本行(heap tuple)仍然不超过 8KB,保持了行不跨页的约束,同时又支持大字段。
我们可以把用户定义的表叫做主表,而把TOAST存放的表叫TOAST表。
TOAST表的结构
上面已经提到TOAST是以chunk的形式存储,实际上除了chunk以外TOAST表上还有一些其他字段。由于有些系统表本身包含TOAST表,因此可以直接如下SQL找一个TOAST表,并用\d查看TOAST表结构(注意的是TOAST表存放在pg_toast schema下,访问时要加上schema名);
select relname from pg_class where relname like '%toast%' and relkind='t' limit 1;
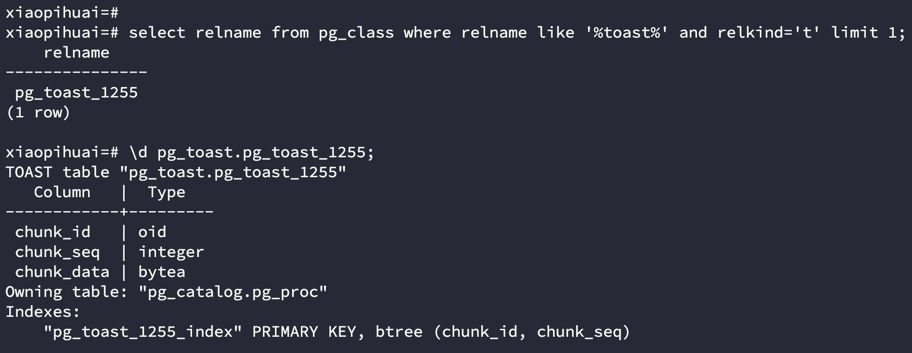
可以看到,整个TOAST包含3个字段和一个索引,这3个字段含义如下:
- chunk_id: TOAST对象的唯一标识符,一个chunk_id表示一条被切分的主表数据,比如1MB的数据会切成1MB/2KB条TOAST记录,这些TOAST记录的chunk_id相同,主表上存放的TOAST指针里面包含了chunk_id字段,在扫描某个大字段时,只需要把所有该chunk_id的所有数据扫描出来即可。
- chunk_seq:当一个字段被TOAST存储时,如果被切成多条了TOAST,则通过chunk_seq的顺序组织数据,确保分片之间的有序。
- chunk_data:实际存储的数据块,通常越2KB左右
同时可以看到TOAST表在(chunk_id, chunk_seq)建了联合主键索引,这是为了加速查找,首先定位到chunk_id,然后按照chunk_seq扫描该chunk_id下的所有数据块即可。
TOAST表的创建时机
前面我们一直再说超过2KB就会按照TOAST存储,那么什么样的表会创建TOAST表,比如create table t(a varchar(1000))会创建TOAST表吗?
数据存储策略
PostgreSQL中数据的存储类型分4类,不同存储类型对应了不同的存储策略
- PLAIN:不压缩、不线外存储(适用于固定长度类型,如整数)。
- EXTENDED:允许压缩和线外存储(大多数可变长类型的默认策略)。
- EXTERNAL:允许线外存储但不压缩(适合频繁读取的场景,如大文本字段)。
- MAIN:允许压缩和可线外存储(在无法压缩时自动转为线外存储)。
对于这4种存储策略来说,MAIN策略是比较特殊的存在,MAIN的特点如下: 1. 优先压缩(与EXTENDED相同) 2. 即使压缩后仍大于TOAST阈值,也尽量尝试存储在主表行内 3. 只有实在放不下(超过页面容量)时才使用TOAST 4. 介于PLAIN和EXTENDED之间的折中方案
MAIN之所以叫MAIN,是有主存的含义,意思就是尽量放在页面内,MAIN先选择压缩,压如果压缩后的MAIN的数据仍然大于2KB,只要能在页内存的下就可以存储,不需要TOAST,因此如果数据访问频繁,且数据介于2KB~8KB,则可以使用MAIN。
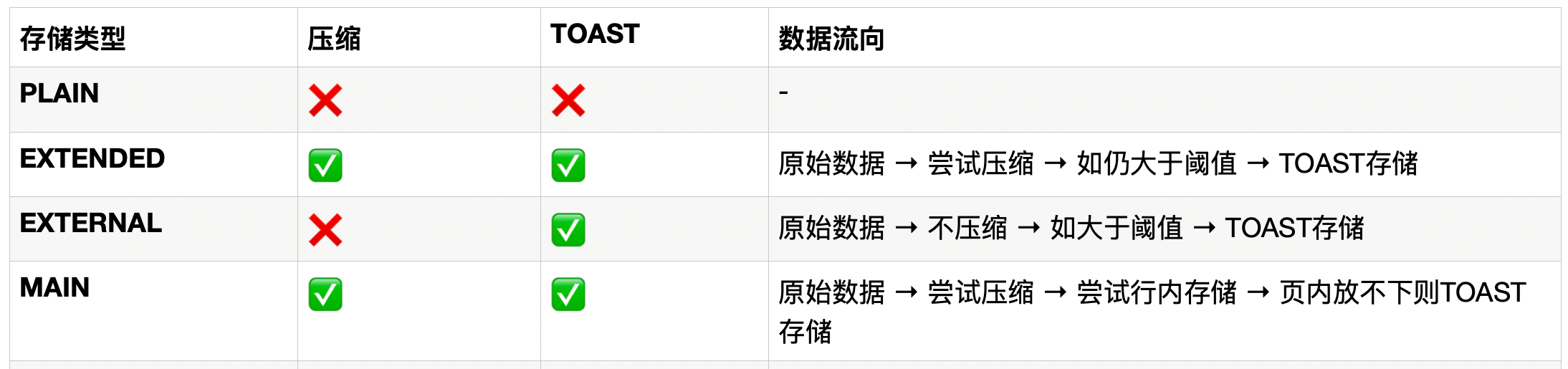
由此可见,对于大字段并不是暴力的按照TOAST切分存储,有些存储可能优先选择压缩,毕竟对大字段先压缩后再TOAST也能减少TOAST分分片,对空间都是有利的。通常我们创建的varchar、text等类型都是EXTENDED的,也就是先压缩在存储。
我们可以在创建表时可以指定text b storage main来执行存储策略,或者通过alter table t2 alter column b set storage main;来修改存储策略。
我们分别用EXTENDED和MAIN创建两个表:
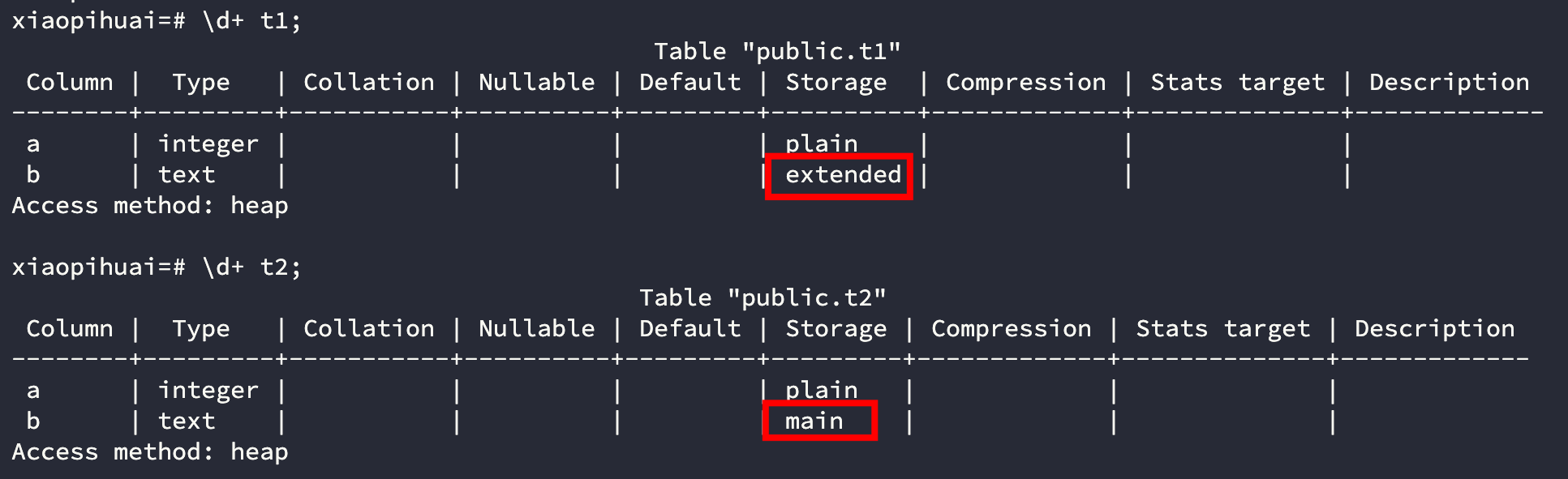
然后给两个表分别插入一条2500的随机字符,之所以随机是为了避免压缩,因为字符有规律重复后压缩率会比较高,只有完全随机字符串才能避免被压缩。 我们用pageinspect来查看元组在页面上的存储长度
CREATE EXTENSION IF NOT EXISTS pageinspect;
SELECT lp_len FROM heap_page_items(get_raw_page('t1', 0));
SELECT lp_len FROM heap_page_items(get_raw_page('t2', 0));
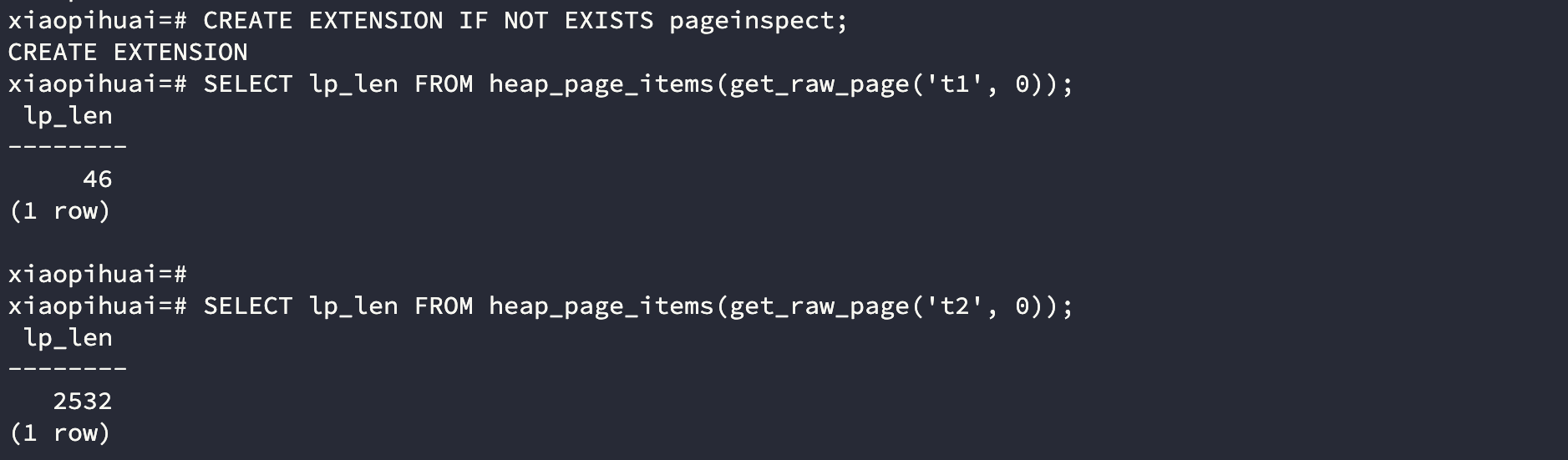
可以看到,t2表的b字段是MAIN类型,且插入了长度为2500的字符串而并未触发TOAST。
创建TOAST时机
前面我们提到varchar(1000)会不会创建TOAST,我们实际看一下:

可以看到,虽然我们只创建varchar(1000),但仍然创建了TOAST,这是为什么?其实这和计算列的长度有关,具体在函数heapam_relation_needs_toast_table中实现的,该函数计算了表的总列宽用于判断是否需要创建TOAST。
static bool heapam_relation_needs_toast_table(Relation rel)
{
int32 data_length = 0;
bool maxlength_unknown = false;
bool has_toastable_attrs = false;
int32 tuple_length;
// 循环判断所有列
for (i = 0; i < tupdesc->natts; i++)
{
Form_pg_attribute att = TupleDescAttr(tupdesc, i);
if (att->attisdropped)
continue;
// 对齐长度
data_length = att_align_nominal(data_length, att->attalign);
// 固定长度则直接累加
if (att->attlen > 0)
{
/* Fixed-length types are never toastable */
data_length += att->attlen;
}
else
{
// 边长类型则计算最大长度,varchar(1000)的1000存放在atttypmod字段
int32 maxlen = type_maximum_size(att->atttypid,
att->atttypmod);
// 未定义的长度,如 text、blob等蕾西,maxlen返回-1
if (maxlen < 0)
maxlength_unknown = true;
else
data_length += maxlen;
// 除了PLAIN存储策略,其他的存储策略都可能可以TOAST
if (att->attstorage != TYPSTORAGE_PLAIN)
has_toastable_attrs = true;
}
}
// 都是PLAIN类型,不需要TOAST
if (!has_toastable_attrs)
return false; /* nothing to toast? */
// 由未定义长度的类型,创建TOAST
if (maxlength_unknown)
return true; /* any unlimited-length attrs? */
// 计算tuple的长度(包括bitmap)
tuple_length = MAXALIGN(SizeofHeapTupleHeader +
BITMAPLEN(tupdesc->natts)) +
MAXALIGN(data_length);
// 如果tuple长度大于TOAST阈值,返回true
return (tuple_length > TOAST_TUPLE_THRESHOLD);
}
整个计算长度的过程中,关键在于type_maximum_size函数,这个函数又调用了pg_encoding_max_length,pg_encoding_max_length函数又调用了关键的结构const pg_wchar_tbl pg_wchar_table[],pg_wchar_table中定义了各种编码的最大编码字节。
typedef struct
{
mb2wchar_with_len_converter mb2wchar_with_len; /* convert a multibyte
* string to a wchar */
wchar2mb_with_len_converter wchar2mb_with_len; /* convert a wchar string
* to a multibyte */
mblen_converter mblen; /* get byte length of a char */
mbdisplaylen_converter dsplen; /* get display width of a char */
mbchar_verifier mbverifychar; /* verify multibyte character */
mbstr_verifier mbverifystr; /* verify multibyte string */
int maxmblen; /* max bytes for a char in this encoding */
} pg_wchar_tbl;

可以看到,UTF-8单字符最大需要4字节编码,通过\l可以看到我们的库就是UTF-8编码。因此当我们创建varchar(1000)时,实际存储是按照1000*4长度来计算长度的,这超过了TOAST的阈值,因此胡创建TOAST表。

我们可以在建库的时候指定Encoding为SQL_ASCII,一个字符按照1字节编码,创建varchar(1000)则不会创建TOAST。
create database db1 template template0 encoding 'SQL_ASCII';
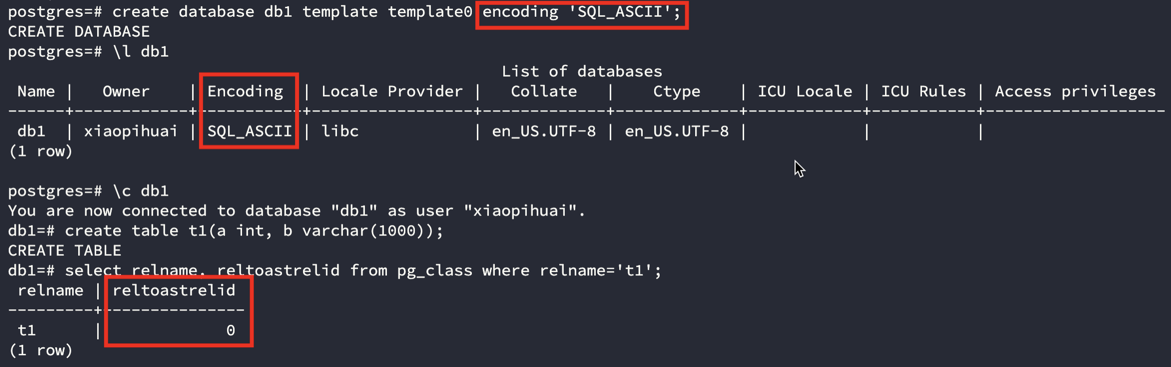
而只有当我们创建超过2000长度的varchar时才会创建TOAST,如下所示:

因此大家平常所说的长度超过2000就创建TOAST这句话并完全准确,这里的2000指的是字节数,varchar(1000)定义的是字符数,当考虑到字符编码时,字符数和字节数并不相等。
TOAST POINTER
TOAST POINTER对用户是完全透明的,是存储引擎内部使用的结构,但是通过了解TOAST POINTER有助于更深入了解TOAST内幕。首先我们要知道的是,当我们把数据使用TOAST存储时,主表上存的是什么?其实主表上存的就是TOAST POINTER。
在学习TOAST POINTER之前,我们先学习下Postgres中对变长字符串的表示。和绝大部分系统一样,Postgres使用了一个标准头来记录字符串的长度,不同是随着字符串的长度不同,这个头也不相同,不过Postgres抽象了结构体varattrib_1b,如下所示,但是具体的存储需要根据va_header的高或低2bit来判断。
在小端模式下定义如下:
xxxxxx00 4-byte length word, aligned, uncompressed data (up to 1G)
xxxxxx10 4-byte length word, aligned, *compressed* data (up to 1G)
00000001 1-byte length word, unaligned, TOAST pointer
xxxxxxx1 1-byte length word, unaligned, uncompressed data (up to 126b)
我们把1字节的头叫做短头,4字节的头叫做长头
- 小于126字节的短串;用
create table t3(a text)来创建一张表,插入一条'1234567890'的字符串,通过pageinspect来解析,结果如下:

解析首字节0x17
postgres=# select 0x17::bit(8);
bit
----------
00010111
(1 row)
可见最低bit是1,因此
typedef struct
{
uint8 va_header;
char va_data[FLEXIBLE_ARRAY_MEMBER]; /* Data begins here */
} varattrib_1b;
┌────────────────────────────┐
│ 0X80 + length │ ← 1字节首字节标
├────────────────────────────┤
│ va_rawsize │ ← 4字节 (原始数据大小)
├────────────────────────────┤
│ va_extinfo │ ← 4字节 (扩展信息)
├────────────────────────────┤
│ va_valueid │ ← 4字节 (TOAST对象ID)
├────────────────────────────┤
│ va_toastrelid │ ← 4字节 (TOAST表OID)
└────────────────────────────┘
TOAST插入流程
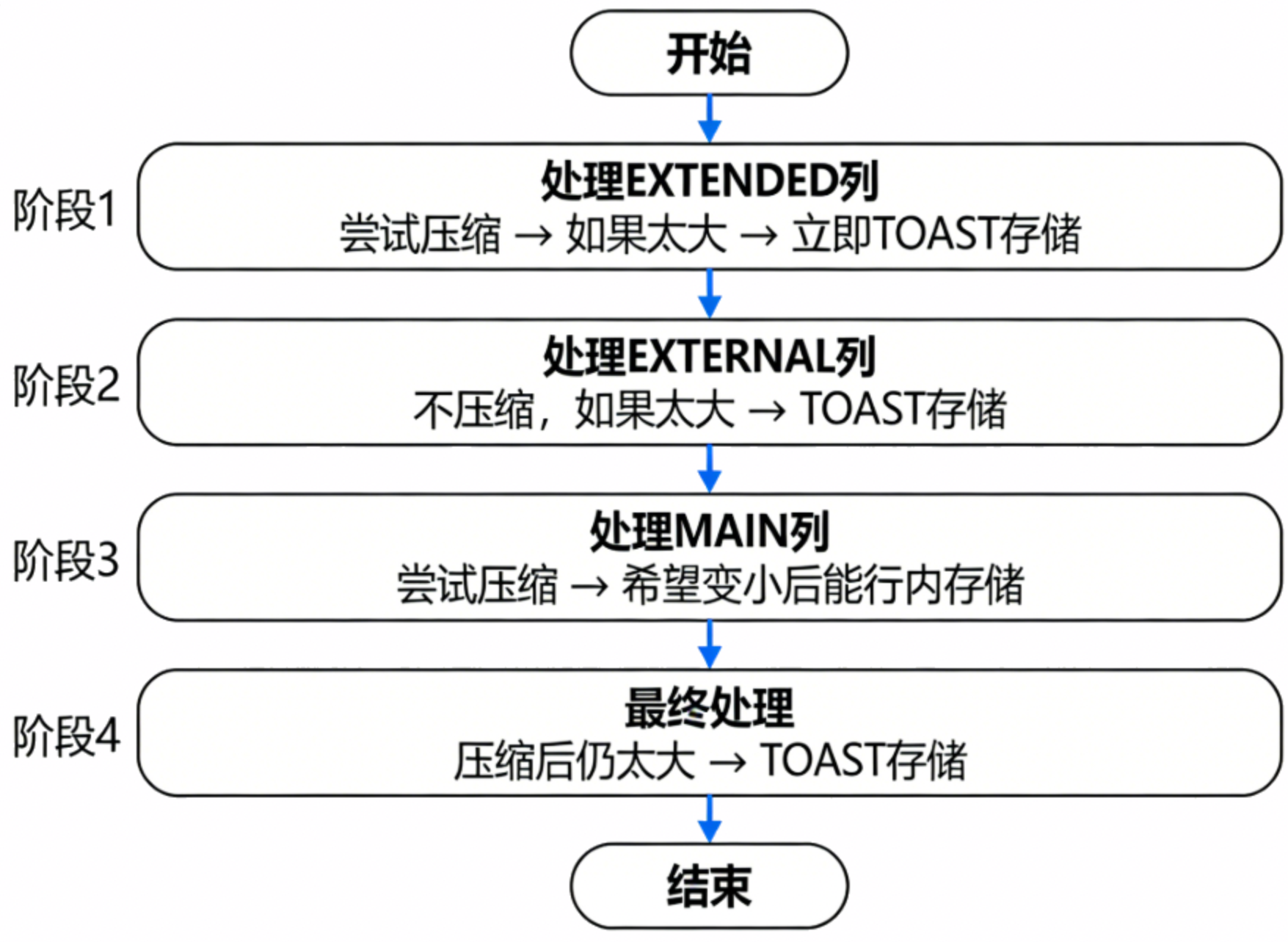
TOAST的插入函数入口是heap_toast_insert_or_update,这个函数很长,总体来说是在处理3种可以TOAST的数据,使得最终能够在页面存的下,大概可以分为4个步骤:
- 阶段1: 处理EXTENDED列,尝试压缩 → 如果太大 → 立即TOAST存储
- 阶段2: 处理EXTERNAL列,不压缩,如果太大 → TOAST存储
- 阶段3: 处理MAIN列,尝试压缩 → 希望变小后能行内存储
- 阶段4: 处理压缩后的MAIN列,压缩后仍太大 → TOAST存储
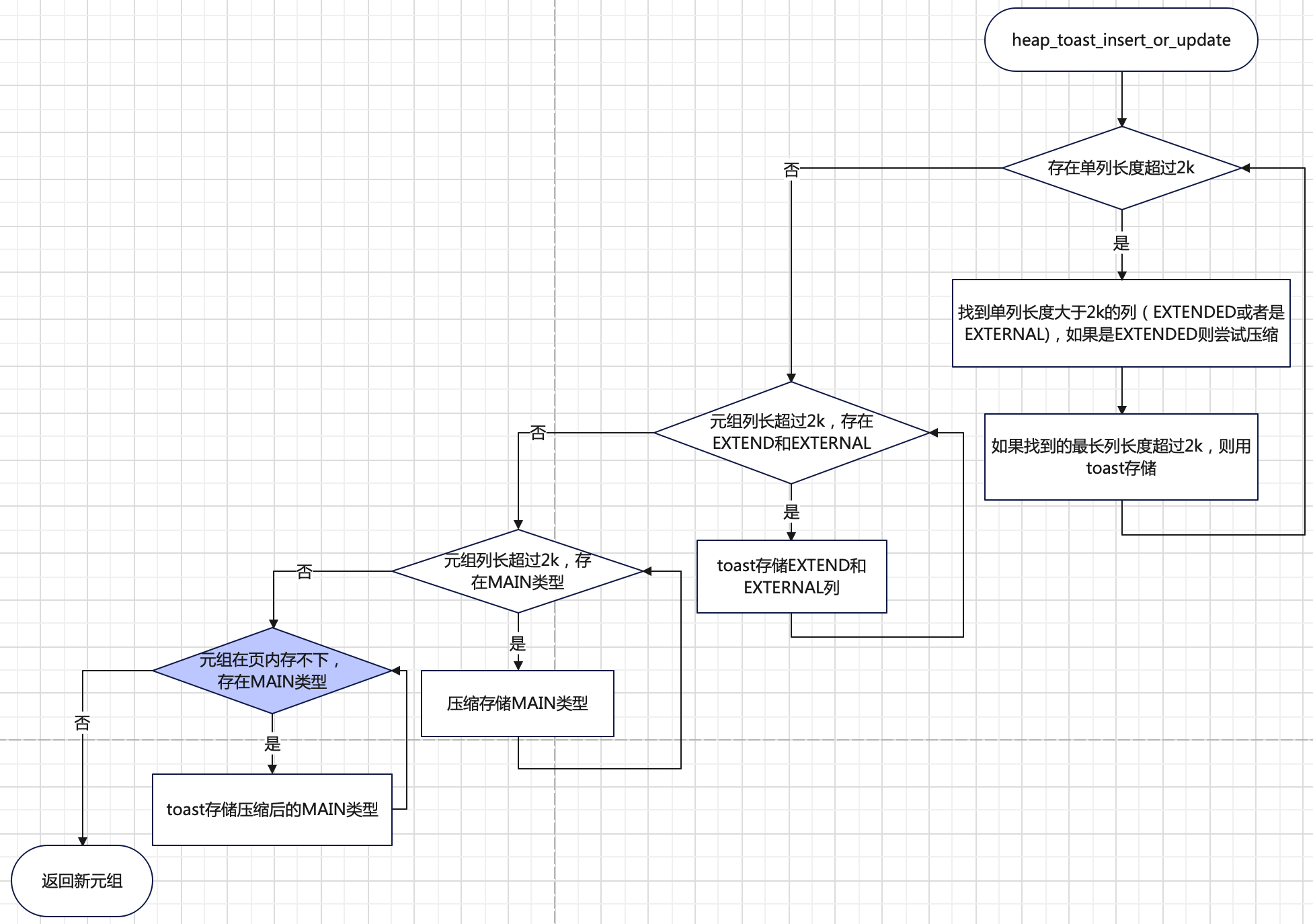
详细的流程如下所示,其实就是按照存储策略优先级,依次处理3中数据,注意的是最后只剩下MAIN时,即使超过了2KB,也不一定会触发TOAST存储,MAIN类型的数据压缩后优先在页内存储,如果压缩后实在存不下(压缩后大于8KB),此时才会把MAIN以TOAST存储。
TOAST表的可见性
整体来说,TOAST不太需要判断可见性,TOAST的可见性完全是跟着主表走的,正常情况下都是先扫描出主表上的TOAST POINTER后再扫描TOAST表。
在返回客户端时,printtup函数会调用text_to_cstring函数来做TOAST数据的还原,通过pg_detoast_datum_packed->detoast_attr最终解析

在detoast_attr中通过索引扫描TOAST表,调用HeapTupleSatisfiesToast判断可见性
上一篇: 脱不掉的长衫不如穿起它
下一篇: 还是应该写点东西

